

It had long since come to my attention that people of accomplishment rarely sat back and let things happen to them. They went out and happened to things.

We will start this post with a story of a big bad launch of software. There was a massive corporation that decided to embark on a project of breaking a massive monolithic piece of software into a million chunks of smaller software - well not literally million but quite a lot of chunks.
There were a lot of teams created - each responsible for their own piece of software. They developed their individual pieces, agreed on contracts amongst themselves, tested the pieces individually, assembled them together and waited with bated breath as they switched the integrated system to start. Nothing happened. The damn thing did not come up.
Four nights of debugging and several coffees later, it was realized that there are too many nested calls between micro services. One micro service called another which called a third one and so on till the call stack started looking more like a tower of Babel.
The biggest victim of this kind of indiscriminate call stacks is availability. As the call stack gets more and more nested, availability decreases dramatically. To explore availability further, let us explore a typical situation in an enterprise application - wherein a client is trying to obtain some data from a server.
In this case, the server provides the data which the client needs. Server also has the proper way of retrieving the data in the way the client needs i.e. the data retrieval process is tied to the client. For example, let us consider a product catalog in a retail enterprise. The search app requires this to be indexed by various product descriptions while the pricing app requires a different way of retrieving of the exact same data.
The typical client-server interaction model is a one-to-one request-response communication protocol. The client issues a request to which the server responds. The server is customized to support various ways in retrieving the data.
Two important paradigms within the client-server interaction model are RPC and Messaging.
Remote Procedure Call (RPC) operates on a synchronous request-response paradigm. RPC clients and server are temporally connected i.e. both need to be up and running at the time of making the call. If the server were down, the client will need some kind of circuit breaker pattern to retry till such time the server is available.
In this paradigm, a highly available message broker intermediates interactions between the client and the server thereby breaking the need for the temporal relationship between them. However this still does not mitigate the temporal relationship between the client and the server. The client processing is still tied to receiving a response from the server. If the server is unavailable for 20 minutes, the product catalog, for all intents and purposes, is unavailable for the same amount of time. So the availability problem persists - albeit without the need for circuit breakers and the like.
The best way to break the availability problem is to create a redundant source of data. The redundant data source services the client even if the server is not available. This hugely increases the availability and in the process buys us considerable freedom. We can structure the data as per the retrieval needs of the client. So we not only address the availability problem but have considerably increased the performance of the application.
We can go crazy and push the data for every client in the enterprise thereby cluttering the enterprise with the same data everywhere. For example, we can create miniature replicas of the product catalog in every system in the enterprise. Alternately we can stipulate some designated sources for this data - anyone who needs the data must tap into one of these designated sources.
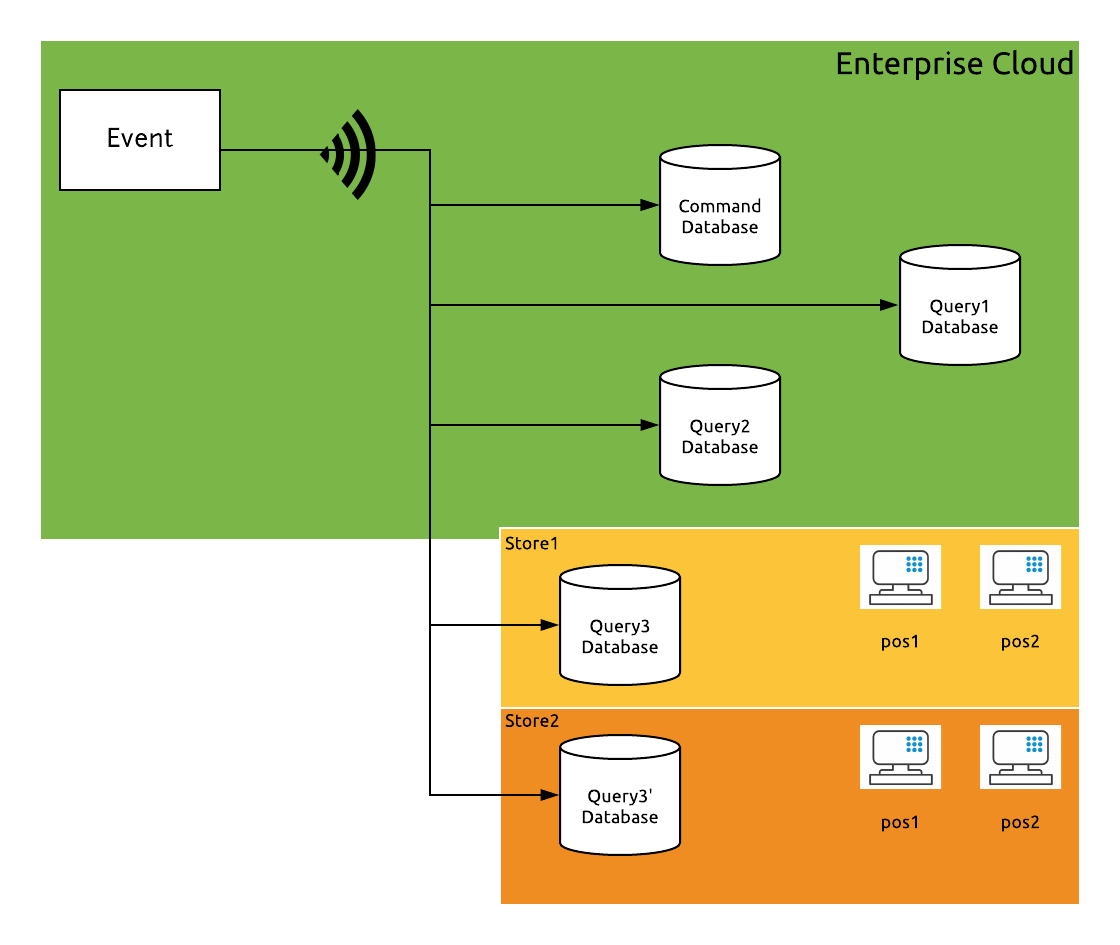
If I design an enterprise service that requires the product catalog, then I will tap into the data source that supports the product catalog retrieval that is most suitable for me. This realization is documented in the CQRS pattern. The Command i.e. the write part is separated from the query i.e. the read part. All reads are serviced by the query DB whilst all the writes are serviced by the command. There can be multiple query databases for the product catalog but there exists only one master source which is called the Command DB. The data diagram illustrates this pattern. But there is more.
Let us say I am automating the stores in a large enterprise. The stores must continue to work even if the connectivity between the store and the rest of the enterprise is down. Hence the product catalog must be replicated in every store. This adds a new dimension to the replication strategy. There must be as many data sources as there are stores!
So the exact same replicated product catalog exists in multiple stores (as shown in the diagram)
How do we make sure that the data can propagate to the myriads of data sources within the enterprise? One way is to make sure that when the data is mutated within the master source then the entire enterprise gets the mutated data immediately. We can transactionally link the entire system to make sure that the data command only returns SUCCESS if all the replicated databases have successfully changed! This gives us data reliability at a huge expense - it sacrifices availability which was the original driver for this exercise to begin with!
Hence the industry has drifted towards a slightly less reliable but a much better option - events. Events are propagated for every data change. These events are used by the individual data bases to mutate themselves. So when a new product (in our example) gets introduced into the product catalog then the product is created by every replica of the product catalog.
This gives us huge availability gains albeit at a slight loss of consistency - a phenomenon called eventual consistency. Eventually the DB becomes consistent. If I might be excused a pun:
Events make the DB consistent - eventually.
Eventing has become mainstream with the huge success of KAFKA and Micro Services. We have witnessed a phenomenal increase in its adoption with multiple event sourcing strategies propounded for data propagation in the enterprise.
But eventing is not always easy to fathom. Canonical event design in a massive enterprise is a gargantuan task that cuts across organizational boundaries. It will involve multiple stakeholders, diverse technology stacks and the resolution of conflicting priorities.
We are in the midst of these exercises in multiple companies. Many a time, I see a lot of confusion about what constitutes an event. How is it different from a message? To which my answer is that events can be messages but not all messages are events.
If a large enterprise were to send ETL feeds everywhere, will it make sense to replace these feeds with events? Is it an incremental ETL strategy? What is the difference between a feed and an event?
These are some of the questions that we will attempt to answer by stating what I call the eight fold path of events as stated in the eight axioms
All events are immutable i.e. the same event will never ever be repeated
This axiom guarantees that once an event is processed by an event consumer, then the effect of the processing will never need to be undone. New events might reverse the affect of an earlier event. However, the existing event stays processed. Its effect is never undone. Example: Let us say that every bank transaction in a savings bank account is sent as an event downstream. Let us also suppose that there was an event for INR 100 Dr. that is already sent. Subsequently it was realized that the event was sent in error and it should actually be INR 120 Dr. Now two events will be sent one for INR 100 Cr. followed by INR 120 Dr. The new event will never mutate the earlier one.
Since events are immutable they leave a traceable log The only way to reverse an erroneous event that was sent previously is to generate a compensating event
This axiom defines “when” the event gets sent.
An event is sent when a change takes place in a bounded context.
A bounded context represents a subdomain that has interesting entities in it. For example a product bounded context has Products in it. As and when things happen to a product, an event will get emitted by the product subdomain.
What this means is that there is a relationship between actions happening in the bounded context and the events being sent. What this also means is that if there is no change in the bounded context then there must be no event sent out. You might say that this is really obvious! But as we discuss further we will realize why this is important.
This axiom has to do with “what” changes an event represents. Let us consider our product catalog example. A product catalog has multiple products with attributes like name, description etc. Products are also associated with prices.
However, price and other product attributes have different axis of change. Prices change more often for a product than other attributes. The stakeholders for price change are different from the stakeholders for addition of new products or for product change. Hence in most retail enterprises, there exist two bounded contexts - Product and Price. Each domain or bounded context has its own axis of change. This axiom tells us what change the event represents.
An event precisely represents the changes occuring for one entity or an aggregate in a bounded context. Corollary: An event cannot be shared across bounded contexts.
So, in the example above, price must have its own set of events (PriceChanged for example) and Product must have its own set of events. Emission of price events is the responsibility of the Price domain and emission of product events is the responsibility of the Product domain.
Typically, this will cut across multiple bounded contexts and has the potential to cause disruption since the ownership of the event gets diluted. In this example, if a client desires that she needs to be notified if anything changes in a product - whether it is a product attribute or product price - then it is not possible if the Price domain is distinct from the Product domain. We would need a consolidating bounded context which unifies both price and product into one entity. This is possible and sometimes desirable as well. But this axiom makes it clear that there is work that needs to be done in unifying the required bounded contexts and generating the event.
This axiom deals with the content of the event.
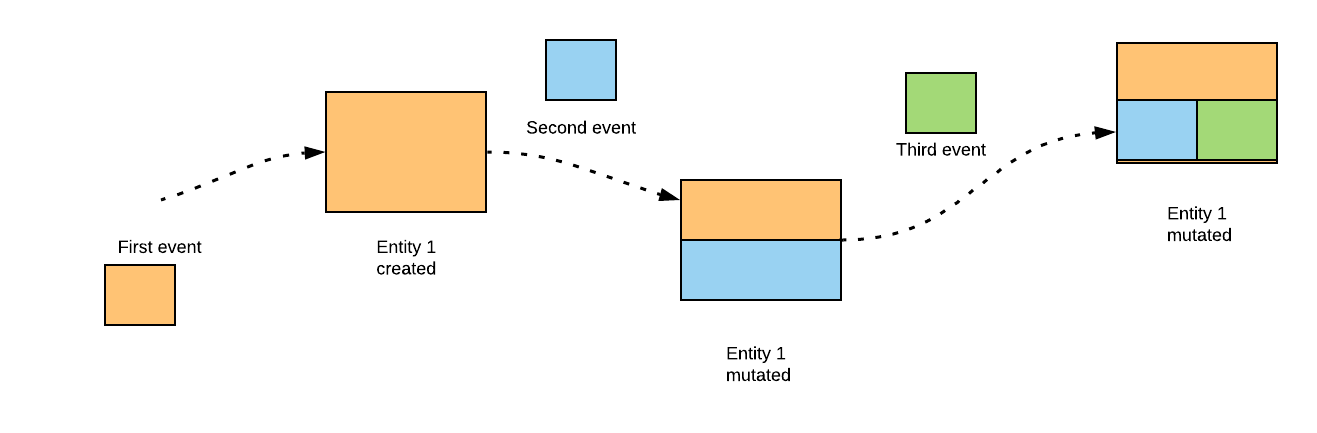
One school of thought is to send the new version of the entity - aka the new entity snapshot. For example, let us say that we are sending events related to products in a product catalog. A product got created. So we send out an event containing the new product that got created. If the product is now mutated, we can then send the new mutated version of the product.
In this way, the systems downstream about the changes that happened to the entity but they dont have to be smart about incorporating these changes into their version of the entity. They merely replace the product snapshot that they carry with the new product snapshot that they received in the event!
An alternative theory is to send so called thin events. In this case, the first event namely product creation in our example, will send out the complete entity as before. However every event post that will only emit changes that are sufficient for data sources to update their version of the entity. This is illustrated in the second diagram in the carousel above. The first event sends out the complete entity whilst subsequent events will only send incremental changes to the entity. This means that the downstream systems that consume this event must be intelligent enough to understand it and mutate their version of the entity accordingly. This leads to the third axiom of events namely:
The thinner the event is, the more intelligent the consumer needs to be.
Sending an event type is the responsibility of one and only one bounded context
In case more than one bounded context is responsible to send out an event, then this will imply that the entity (or aggregate) that is linked to the event is owned by more than one bounded context which violates Domain Driven Design (DDD) principles.
The event must be received by someone who is authorized to receive it - in terms of both event projection and event timing
Let us examine the two types of restrictions that are applicable for event consumers in turn.
This has to do with the number of columns an event consumer is authorized to see. For example, product cost might be restricted to most teams. Only teams responsible for P&L such as finance might be authorized to see this information. Since events are not consumer-aware i.e. the same event is sent to all the consumers, the only way to achieve this restriction is to separate the events. In the example above, this restriction can be achieved by separating the product cost event from the product attribute change event. Only Finance can subscribe to the cost event.
When can an event consumer see the event? For example, let us say that we want to develop a system that emits events for the stock market. The news of an impending IPO might need to be restricted by regulations till the time it is appropriate. On the other hand, there might be departments who would need to know about the IPO in advance to make adequate preparations. So quite clearly, the timing of the event will be different for these different event consumers.
This restriction might be achieved by introducing a new event type. This event type is emitted only when the public must know about it.
Avoid expanding aggregate entities from other bounded contexts in your events
Let us take the example of a Christmas sale. The sale applies to a group of products - for example product 1 and product2. Instead of dealing with too many products, the product domain allows setting up product groups. In this case we can set up a product group PG1 that contains product1 and product2. The sale itself is set up against PG1 (and not against product1 and product2 individually) as part of the Promotion bounded context. Now let us say, the Promotion bounded context wants to send an event when a sale has been set up. It can choose to expand the product group to the constituent products when emitting out the event. Hence the Promotion domain sends this event with product1 and product2 (by expanding the PG1 group into the constituent products). However, there is a problem with this.
This expansion of PG1 to product1 and product2 is applicable only at the time of sending the event. If PG1 were to be altered in the product domain and a new product called product3 was added to PG1, then the event consumers will not know about this change unless the promotion domain were to send out a new sale event for product3. But if you think about it, this violates axiom 1. The Promotion domain is ending up sending events even though the actual event (i.e. adding product 3 to PG1) happened in the Product domain and not within the Promotion domain.
This could have been avoided if the promotion domain did not expand PG1 to product1 and product2 which is the statement of this axiom.
But what if it is desired to have sale events at the product level even though they are set up at the product group level? Then we need to create a new subdomain which is responsible to emit this event.
Events must be self contained. There must be enough information in the event to act on it without needing an RPC call to the same bounded context.
Remember, events are there to enhance availability. If events mandate RPC calls, then most of the problems with availability return back. Hence this should be avoided.
If these principles are followed, events can prove to be extremely beneficial.